
Misconfigurations have frequently been reported as a major source of service outages. Instead of taking a domain-specific approach to combat configuration errors, we present Diffy, a push-button, ML-based tool for automatically detecting anomalies in arbitrary structured configurations.
From a set of example configurations, Diffy synthesizes a common template that captures their similarities and differences (illustrated in the figure above), using a dynamic programming algorithm related to the idea of string edit distance. Diffy then employs an unsupervised anomaly detection algorithm called isolation forest to identify likely bugs.
We assess Diffy against a variety of real configurations, including those from Microsoft’s wide-area network, an operational 5G testbed, and public MySQL configurations. Our results show that Diffy generalizes across domains, scales well, achieves high precision, and identifies issues comparable to domain-specialized tools.
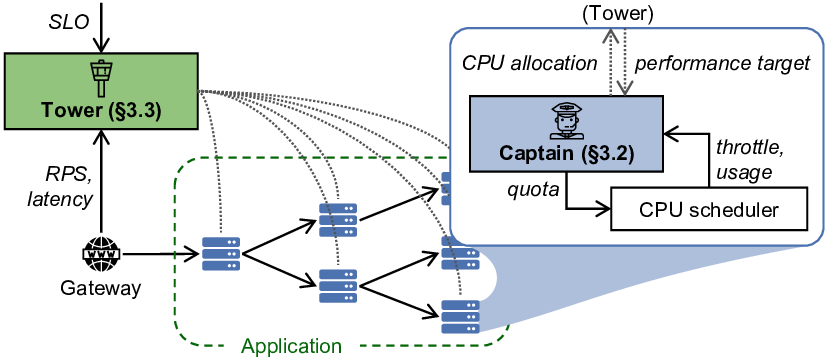
As cloud applications increasingly adopt microservices, resource managers face two distinct levels of system behavior: end-to-end application latency and per-service resource usage. To coordinate them, we developed Autothrottle, a bi-level resource management (CPU autoscaling) framework for microservices with latency SLOs (service-level objectives).
Autothrottle consists of per-service CPU controllers (called Captains) and an application-wide controller (called Tower). The service-level controllers are based on classical feedback control, performing fast and fine-grained CPU allocation using locally available metrics. The application-level controller employs lightweight online learning to periodically compute appropriate performance targets for per-service controllers to achieve. We opt for CPU throttle ratios as the performance targets due to their strong correlation with service latencies, as revealed by our correlation tests.
When evaluated using production workloads from Microsoft Bing, Autothrottle demonstrated higher CPU savings and fewer SLO violations than the best-performing baseline from Kubernetes.
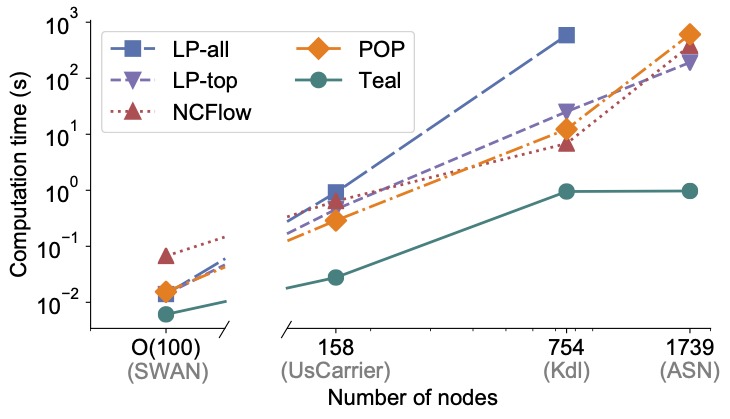
The rapid growth of cloud wide-area networks (WANs) has posed a challenge for commercial optimization engines to efficiently solve large-scale network traffic engineering (TE). Therefore, we created Teal, an ML-based TE algorithm that capitalizes on the parallel processing power of GPUs to accelerate TE control.
Our key insight is that deep learning-based TE schemes — if designed carefully — may harness vast parallelism from thousands of GPU threads, while retaining TE performance by exploiting a wealth of WAN traffic data. To achieve this, Teal carefully employs a flow-centric graph neural network (GNN) for feature learning, a multi-agent RL algorithm for traffic allocation, and a classical constrained optimization method (called ADMM) for solution fine-tuning.
Results in the above figure show that on traffic matrices collected from Microsoft’s WAN over a 20-day period, Teal ran several orders of magnitude faster than the production optimization solver and other TE acceleration schemes (while generating near-optimal allocations).
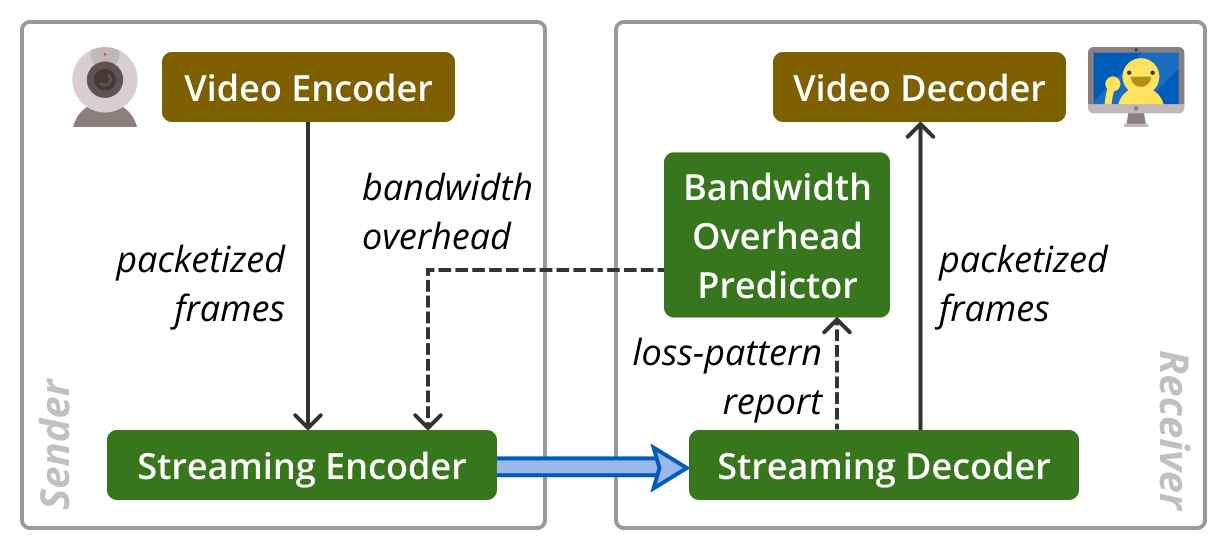
Promptly recovering packet losses in video conferencing is essential to prevent video freezes. In high-latency networks where retransmission takes too long, the standard approach for loss recovery is forward error correction (FEC), which encodes data with redundancy prior to transmission. Nevertheless, conventional FEC schemes are inefficient at protecting against bursts of losses, as we discovered after analyzing thousands of video calls from Microsoft Teams.
Thus, we created Tambur, an efficient loss recovery scheme for video conferencing. Tambur combines a theoretical FEC framework known as streaming codes with a lightweight ML model that predicts the bandwidth allocation for redundancy. The overall architecture of Tambur is shown in the figure above.
To validate Tambur’s performance, we implemented a video conferencing research platform called Ringmaster, with an interface for integrating and assessing new FEC schemes. Using a large corpus of production traces from Teams, we demonstrated — for the first time — that streaming codes can improve the QoE for video conferencing.
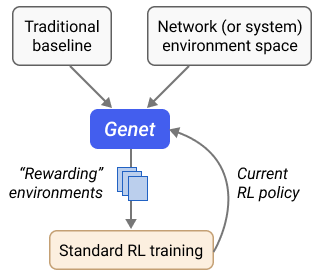
Despite a flurry of RL-based network (or system) policies in the literature, their generalization remains a predominant concern for practitioners. These RL algorithms are largely trained in simulation, thus making them vulnerable to the notorious “sim-to-real” gap when tested in the real world.
In this work, we developed a training framework called Genet for generalizing RL-based network (or system) policies. Genet employs a technique known as curriculum learning, automatically searching for a sequence of increasingly difficult (“rewarding”) environments to train the model next. To measure the difficulty of a training environment, we tap into traditional heuristic baselines in each domain and define difficulty as the performance gap between these heuristics and the RL model. Results from three case studies — ABR, congestion control, and load balancing — showed that Genet was able to produce RL policies with enhanced generalization.
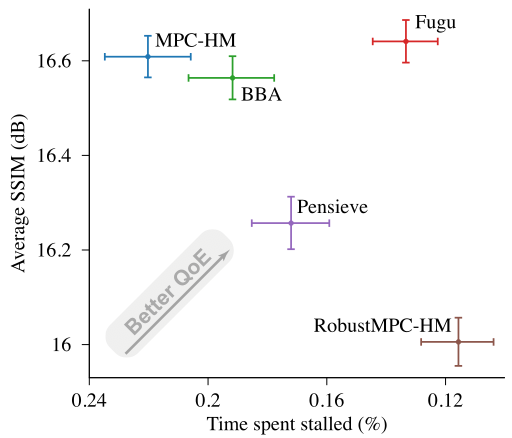
On-demand and live video services deploy adaptive bitrate (ABR) algorithms to dynamically adjust video bitrates in response to varying network conditions, aiming to optimize the viewer’s quality of experience (QoE). To measure the behavior of ABR algorithms on real networks, we built Puffer, a freely accessible video service that live-streams seven over-the-air television channels.
Puffer operates as a randomized controlled trial of ABR algorithms on more than 360,000 real users amassed to date (as of July 2024). In this real-world setting, we found that an RL-based ABR algorithm surprisingly did not outperform a simple rule-based algorithm. This is because the RL algorithm was trained in simulated networks, which failed to capture the vagaries of the wild internet.
Therefore, we designed Fugu, an ML-based ABR algorithm trained in situ, directly on data from its eventual deployment environment, Puffer. Fugu integrates a classical control policy, model predictive control, with a neural network for predicting video transmission times. After streaming decades’ worth of video through Puffer, we demonstrated that Fugu robustly delivered higher QoE than other ABR schemes (as shown in the figure above).
We have opened Puffer to the entire research community for training and validating novel streaming algorithms and released collected data on a daily basis. Since then, Puffer has assisted researchers in publishing papers at top-tier conferences, including CausalSim at NSDI ’23 (Best Paper Award) and Veritas at SIGCOMM ’23.
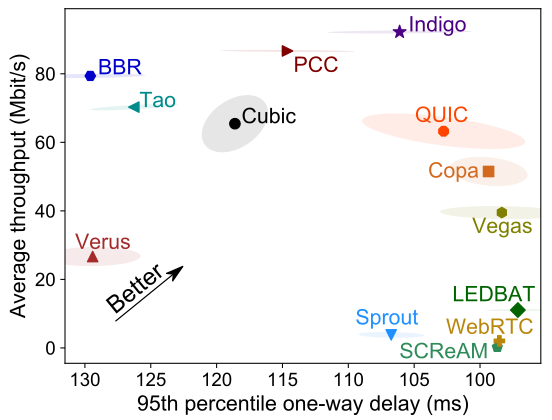
The performance of network applications hinges on effective internet transport algorithms. However, researchers often find it challenging to evaluate new transport schemes in a generalizable and reproducible manner due to the absence of a large-scale, publicly accessible testbed.
To address this, we developed Pantheon, a distributed “training ground” for internet congestion control research. Pantheon offers a software library to test a common set of benchmark algorithms, a worldwide testbed of network nodes on wireless and wired networks, a public archive of results, and a collection of calibrated network emulators automatically generated to mirror real network paths with high fidelity. Since its launch, Pantheon has aided in the development of over 10 congestion-control algorithms published at top-tier conferences such as SIGCOMM and NSDI.
Additionally, Pantheon also supported our own ML-based congestion-control scheme, Indigo. The key idea is that for emulated (or simulated) networks, the ideal congestion window can be closely approximated by a classical concept in congestion control known as the bandwidth-delay product (BDP). This enables “congestion-control oracles” that continuously steer the congestion window toward the ideal size, thus allowing Indigo to mimic these oracles using a state-of-the-art imitation learning algorithm. After further integrating calibrated emulators into training to bridge the gap between emulation and reality, Indigo achieved generalizable performance on the internet (as shown in the figure).